
Some recent reading brought the concept of a 10X Engineer to my attention, specifically an article titled: “The 100x Engineer”. This is a concept that I had no knowledge of prior to this revelation but after digging deeper there is quite a large amount of information regarding this philosophy out there on the web. In case you are not familiar with the concept, a 10X Engineer is someone that could produce about 10X more than an average Engineer at a company. Done. That is the concept in a nutshell. Take a moment here and step back. We will dive into the concept in a second, but first, think about all of the things in your life that would change if some of them were 10X. Sure, we would all love a 10X bigger paycheck. What if your internet was 10X faster? Or your car was 10X more fuel efficient? What if you worked out so much that you needed to eat 10X the calories to balance out the workouts? What if things changed in a way where you had a need to buy 10X toilet paper? The concept is a little far-fetched when you stretch it out like this, yet the concept exists and is discussed broadly on blogs and in Engineering circles. So where did it come from?
The genesis of this idea stems from an experimental study done in 1968 titled “Exploratory Experimental Studies Comparing Online and Offline Programming Performance”. The title is linked to an apparent scanned copy of the paper that can be found on the Electrical Engineering and Computer Science site for the University of Michigan. It is an interesting read but may seem a little outdated to any younger readers. Some introduction may be needed. As this is written in 2019 we are all familiar with the concept of carrying a tiny little computer in our pockets that has more than 1,000,000 times more memory and over 100,000 times the processing than the computers used to get humans to the moon and back in 1969. These numbers came from a fascinating article comparing the Apollo 11 systems to a mobile phone: “Your Mobile Phone vs. Apollo 11’s Guidance Computer”. However, back in the 1960’s, computer time was both much more expensive and much more limited than it is today. In fact, the availability of computers at that time was so constricted that in most settings programmers would write code independently of computers.
On paper.
With a pencil.
Or if they were daring and a really proficient programmer, with a pen.
To illustrate this point, from the experimental study link the following statement is made regarding the use of an IBM AN/FSQ-32 computer for this research:
When a user wishes to operate his program, he goes to one of several teletype consoles; these consoles are direct input/output devices to the Q-32. He instructs the computer, through the teletype, to load and activate his program. The system then loads the program either from the disk file or from magnetic tape into active storage (drum memory). All current operating programs are stored on drum memory and are transferred, one at a time, in turn, into core memory for processing. Under TSS scheduling control, each program is processed for a short amount of time (usually a fraction of a second) and is then replaced in active storage to await its next turn. A program is transferred to core only if it requires processing; otherwise it is passed up for that turn. Thus, a user man spend as much time as he needs thinking about what to do next without wasting the computational time of the machine.
The concept of writing software on paper before programming it into a computer is the basis for the experimental study. The goal of the experimentation was to compare the efficiency of people writing code on paper against writing code on a computer. The method used for experimentation was categorized as online against offline programming. The paper states that the “online” components were easy; the programmers were instructed “to use TSS in the normal fashion” meaning that they were using the computer directly for debugging. The offline programming required more planning in order to achieve the goals of the study. The resulting methodology for the offline programming required the programmer to not only submit the code to be executed, but to also submit a work request containing specific instructions to be followed for the execution of the written program to be done by a member of the experimental staff. It is a crucial point in the paper that all programmers were actually writing their programs offline. This is called out in the following:
Each programmer was required to code his own program using his own logic and to rely on the specificity of the problem requirements for comparable programs. Program coding procedures were independent of debugging conditions; i.e., regardless of the condition imposed for cheekout–online or offline–all programmers coded offiine. Programmers primarily wrote their programs in JTS (JOWAL Time-Sharing—a procedure-oriented language for time sharing).
Simply put – this statement means that the work done in this paper does not target the act of creating code on a computer versus the act of creating code on paper. Any difference in the time to generate code for this test is on a comparison between individual programmers, not the overall process or the computers used in the test. What it does compare is the act of debugging. This is a critical distinction in this paper. The measurements taken do not directly reflect programming ability and while there is an insinuation of causation between the ability of a programmer and the amount of time needed to debug, causality cannot be determined based on the data available.
This analysis and identified gaps of the original of the 10X methodology are not new. There are many questions that can be asked of the study and the results implied therein. These questions have been asked by many others before my humble analysis. The initial thought that struck me is that the sample size of the programmers is extremely small. Next, the first part of the study dealt with seasoned programmers who were asked to program both a solution for interpretation of algebraic equations and a solution to determining a path through a 20×20 cell maze. There were 5 performance variables tracked for each test (Algebra test and Maze test) but no corroborating data that would indicate which of these variables applied to the programmer that generated the data. These included Debug hours, CPU time, Code hours, Program size, and Run time. The paper calls out a ratio between the highest performing individuals in the test and the lowest performing individuals in the test for each of these metrics as shown below.
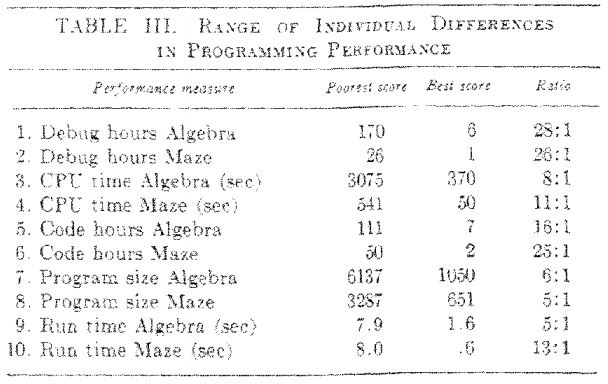
What this does not show is any correlation between each metric per individual. Instead, a broad generalization is drawn across the board simply based on the ratio provided for each metric with a spotlight placed on the differences that show “an order of magnitude” difference between the best and poorest scores resulting in a ratio difference greater than 10:1 for 6 of the 10 metrics. The paper then focuses on the “poorest” scores with a nursery rhyme:
When a programmer is good,
He is very, very good,
But when he is bad,
He is horrid.
The idea of the 10X programmer is born shortly thereafter as the “horrid” performance is further analyzed. The study states that “one poor performer can consume as much time or cost as 5, 10, or 20 good ones.” The author of the paper does make a halfhearted attempt to further expound on this topic stating that “techniques to detect and weed out these poor performers could result in vast savings in time, effort, and cost.” It then carries on by stating that an exploratory analysis was conducted on the “intercorrelations of 15 performance and control variables” with a rather weak conclusion that “programming speed” marked by faster coding and debugging and program economy marked by shorter and faster running programs could help to identify which programmers are good and which are poor.
I am left feeling a bit underwhelmed by these conclusions.
They seem rather generalized with no real effort put towards investigating the “intercorrelations”. Where is the analysis of code hours vs debug hours? What if one of the programmers performed the poorest in regards to coding time on the Algebra test (111 hours) but performed the best in terms of debug hours for this test (6 hours)? That would be 117 hours of total time and what if the fastest programmer (7 hours code time on the Algebra test) took the longest to debug (170 hours) for a total of 177? The study seems to want to draw causality between the fastest programmers and the least amount of time to debug because they want to call out the “Best” programmers against the “Poorest”. In my experience I have observed plenty of examples that would refute this. Finishing a program the fastest typically leads to more debugging time needed as not all variables have been accounted for and edge cases have not been considered properly.
While there is a lot more to this study including attempting to draw additional conclusions from a set of entry level programmers in the second part of the study, let’s step back here and go back to the idea of a 10X Engineer. The interpretation section of the experimental study does attempt to call out possible issues with the conclusions about to be drawn. The paper identifies the very small count of individuals who participated in the study and therefore the large range of results created subsequent large error variances that calls into question the riskiness of drawing any solid statistical inferences from the study. This section also calls into account the potential “representativeness of these problems for programming tasks” as an unknown variable. This means that they really aren’t sure that the coding scenarios that were used are good enough to draw generalized inferences from and that there may be variables that they are not considering that could generate false conclusions. The section finishes up with a warning that the upcoming interpretation of results is discussed under broad topics instead of detailed conclusions and further goes on to state that the two experiments should consider and emphasize “their tentative, exploratory nature – at best they cover a high circumscribed set of online and offline programming behaviors.”
Yet even with these warnings, small sample size, and the broad, generalized nature of the interpreted results still result in bolstering the argument for a 10X programmer methodology. The paper even doubles down in section 3.2:
These studies revealed large individual differences between high and low performers, often by an order of magnitude. It is apparent from the spread of the data that very substantial savings can be effected by successfully detecting low performers. Techniques measuring individual programming skills should be vigorously pursued, tested and evaluated, and developed on a broad front for the growing variety of programming jobs.
Um…yes? Isn’t this just another way of stating something that common sense should dictate Engineering Managers should already be doing? Don’t we want higher performers on our teams? Won’t they produce substantially more? Yes, yes, and yes. Of course we want all of these things for our teams. What the paper doesn’t delve into but does call out is that determining ways and methods for identifying and programming proficiency and quantifying the right abilities that are exemplified in someone who could be considered a 10X Engineer is very hard to do. Human nature is the barrier here. If anyone could come up with a standardized test that would definitively show the rank of an Engineer, be that of a 1/2X Engineer, a 2X Engineer or a coveted 10X Engineer, then that person would be sitting on a gold mine. That type of test doesn’t exist – probably because the make up of humans that fit into that category is as wide and varied as the range of available Engineers across the world. The experiences, education, training, and personalities of humans cover a vast range of abilities that one simplistic standardized test cannot hope to fully encompass the full breadth of people out there in any meaningful way. So can this 10X methodology just be summed up by stating that Engineering Managers should just try and find the best people?
Let’s jump back to the original article, “The 100x Engineer”. The author, Mr. Hemel, describes spending some time with a new Engineer who was joining his team. He was struck by one of the future goals as stated by this Engineer: “I want to be the best programmer in the world“. Mr. Hemel goes on to describe concepts and traits not just for a 10X Engineer, but for a “100X mindset” which he describes as “a particular way of thinking, talking, and acting” that is boiled down to two primary aspects, ownership and challenging the status quo. He then goes on to describe skillsets for a 100X’er that are above and beyond that of a simple 10X programmer: Communication, Creativity, Empathy, Negotiation, and Technical. While I agree with the stated definition of a 100X’er, it is my opinion that the definition can be further expanded to better define how someone at this ability level adds value to an organization.
Thus, I am adding another ‘0’ to the terminology and stating the rationale for what it takes to be a 1000X Engineer.

To define how someone can add 1000 times the value of a normal employee, it should be recognized that we are talking about a very special skill set. First of all, the concept of someone being 1000 times more valuable to an organization may come across sounding like it is a little over the top, but try and look at it from a different angle. If we consider that a normal programmer is a 1X, that person is equivalent to 10^0, or in another form, has 0 impact to an organization. Sure – that person might hit some targets and get some work done but they are probably there to punch a clock and get paid. They don’t really add anything. How about this thought – when was the last time a hiring manager of any type tried to hire a 0? Sure, sometimes you end up with a zero. Maybe they just happen to interview really well before slumping back into obscurity behind a desk. The point is, managers try and get the best candidate possible. They are always looking for the diamond in the rough, the best and brightest. Nobody goes into an interview looking for simply “meh”.
Great! So let’s go after the 10X’ers. These people are equivalent to 10^1 and reflect that as they have a positive, non-zero impact to an organization, but still they are just a normal 1. The people that managers really want are beyond the 10X’ers. How about a 100X or 1000X person? They are the equivalence of 10^2 or 10^3 and provide 2-3 times the impact to an organization of a 10X person. In this manner I am attempting to describe impact in terms of a logarithmic function because, let’s face it, there is nothing linear about impact, abilities, and humans. There is no way to determine if one Engineer has twice the knowledge in regards to a coding language versus another Engineer. Adding a second resource on a project never halves the development time. However, this theory is stating that impact can be measured. Providing twice the impact to an organization has ripple effects throughout the people and products being created that can certainly justify the 100X terminology.
There is some good news and bad news here. If you are an Engineer and think that you are in the 100X or even the up in the lofty 1000X range you aren’t going to get paid orders of magnitude over those around you. Sorry for the bad news, but reality just doesn’t work that way. If you are an Engineering Manager the news here is both good and bad as well. The good news is that there may be an easy method to determine where people are on this impact scale. The bad news is that just like the experimental paper calls out, there is still no concrete method to identify these types of people up front in the hiring process.
Method for Determination of a 100X or 1000X Engineer
Thinking through this topic has identified an easy way for a manager to identify the amount of impact that someone has. The theory is very simple. Consider a snapshot of the roles and responsibilities that a person is currently doing right now, today, and determine how many replacement people you would need to fill all of those roles if that person was no longer on the team. This fits in very well with the impact idea. If the work that that person is doing could be absorbed easily between other people or is not necessary or valuable enough to even consider a replacement then you have a 0 (AKA a 1X’er). If that person is basically doing exactly what is in their job description and you could swap 1-for-1 with a new person in exactly that same description then that person has an impact of 1, or is essentially a 10X’er. It should be noted that this does somewhat change the definition and description of a person defined as a 10X’er from the paper discussed above. Now we aren’t talking about someone who is 10X faster at coding or debugging or efficiency. We are talking about someone who has a neutral impact of 1 to the overall organization, or in other words, someone who is doing their job as expected.
Applying the same logic to the most impactful people on a team would mean that replacing them would require multiple roles to be filled. Note that these may not be full time equivalencies (FTEs). The concept of a FTE is often used for headcount and finance purposes in an organization, but here we will use it as a metric for determination of impact. To illustrate this idea, let’s consider unisex Engineer Chris. Chris currently spends time developing features for the main product line. Chris also stepped up and is acting as a lead for a secondary project in a role that encompasses both development and project management duties. Chris is also the technical lead for the second biggest customer in the company and attends many weekly meetings and manages technical communications for this customer. As a manager, how would you go about replacing Chris? Depending on how you choose to weight each of these roles, hiring a new full-time developer for the main project is a role in itself. Chris is now worth 1.0 FTEs. Maybe the PM functions for the secondary project could be absorbed or shared but the development time would need a good chunk of time so this role would be worth 1/2 a FTE. Chris is now worth 1.5 FTEs. The technical lead role is not a full-time job in that one person doing this full-time would not have enough work to stay busy every week, but it definitely takes up time and effort so it is considered to be worth another 1/2 FTE. Therefore, replacing Chis is worth 2.0 FTEs and it would ideally take at least 2 people to replace them. Using the 10X methodology, Chris provides 2x impact (or 10^2) and is currently operating at a 100X rate.
Using this methodology it is quickly easy to see how people fit into this scheme. Maybe someone is designing and acting as an architect on a new product. Maybe they are mentoring teammates. Maybe they are just so smart and efficient that they can produce twice as much as an average Engineer and have hit 100X status through that alone. It is also not hard to see how someone could either function at a 1000X level either through accumulation of various skillsets in their career and application of those varies skillsets for job functions or during short bursts of project effort.
This theory comes with limits. There are supposed to only be 40 work hours in a week and even if a person blows past that number and works 16 hour days the amount of hours is capped because there are only 7 days in a week. Additionally, humans cannot maintain that type of pace for long without some severe repercussions either mentally or in regards to the quality of their output. Also, while on the subject of humans and endurance, just like emotional feelings the current 10X ranking for someone can change over time. One day someone might just be on a hot streak and appear to do the work of 4 people (10,000X) but burn themselves out so quickly that they struggle to reach 10X status over the next few days afterwards. Hopefully the roller coaster is not this quick and people are moving up and down more gradually as projects ebb and flow.
How to Identify 100X and 1000X Engineers

Now we get to the hard part. While doing research for this post I ended up reading an engrossing treatise titled “A Study of Sabermetrics in Major League Baseball: The Impact of Moneyball on Free Agent Salaries”. This paper was one that showed up when I was researching a stat in baseball called WAR. This is an acronym for Wins Above Replacement and attempts to show how valuable a baseball player is in comparison to their peers. WAR comes from a collection of “analytical gauges” for player performance that were considered to be a better indicator of player contributions and allowed for identifying hidden value in overlooked players. These metrics are referred to as sabermetrics and have continued to expand across the sporting world over the past decade. The origins of the implementation of these metrics are attributed to the cash-strapped 2002 Oakland Athletics and their manager, Billy Beane. If any of this sounds familiar it may be due to both a bestselling book describing this concept called Moneyball by Michael Lewis (Amazon referral link). It has also been expressed in movie form via a movie of the same name starring Brad Pitt, Robin Wright, and Jonah Hill (Moneyball the movie).
So why can baseball generate deep metrics for each player that produces statistics like WAR that tell a story through numbers but Engineering Managers still manage to occasionally hire zeros despite their best intentions? The experimental study talked about in the first half of this post delving into tests and metrics for evaluating programmers. They spend a lot of time talking about the BPKT – Basic Programming Knowledge Test “a paper-and-pencil test developed by Berger, et al., 1966 at the University of Southern California“. Unfortunately, in the conclusion section they invalidate this as a measure: “The observed pattern was one of substantive correlations of BPKT test scores with programmer trainee class grades but of no detectable correlation with experienced programmer performance.”

In performing this research, one of the big differences that stand out between Major League Baseball and Engineering is the consistency of statistics in baseball. This isn’t just in the big leagues. Statistics are rife throughout all levels of baseball. Triple-A down to Single-A. College. Little League. Stats are kept from top to bottom. I have even kept a scorebook that shows every pitch, hit, walk, ball, and strike for my 11 year old daughter when she was playing softball. Generating deep metrics that show more than simply a home run count is easy to do in baseball. But there are no common statistics for Engineers.
Sure, some random company might be on its “A-Game”. They might have an automated system set up that tracks agile point velocities, Lines-Of-Code (LOC) counts, defect rates of bugs-per-LOC-per-developer, punch card access for time at work, and amount of time spent surfing Medium.com during the work day. Ignoring the triviality of some of these metrics in their ability to provide value, at the root these are all trailing metrics in the sense that someone has to be hired and come to work for a while before any of this data can be collected. This data, were it to be collected, still doesn’t provide any help in the hiring process that an Engineering Manager goes through. There are tons of articles that exist on the web providing helpful tips for identifying 10X Engineers that all seem to focus on data captured post-hire. These are rife with statements similar to this: “after reviewing this information for a year or two the 10X Engineers will stand out like a sore thumb” or something like “Consider: the 10X Engineer you seek might be on your team already.”
So how do you hire a 100X or a potential 1000X Engineer?
The answer here is actually very simple. You don’t. If the data and analysis above doesn’t convince you that there is no definitive method to objectively identify a 100X Engineer in an interview then by all means, have at it. And I wish you good luck. But if you happen to be on the same path and agree with this conclusion, then the next step is to try and identify what things can help in the interview process with the understanding that during interviews people always want to put their best foot forward and the conversations, tests, and interactions don’t always show the true nature of a person. The following is not a concrete method for interviewing. It is, at best, a rough set of guidelines that can be followed and actually is simply just restating ideas that have already been presented in this post. As stated previously, we are dealing with human beings here. Things can get messy at times. The goal here is not to always hire a 100X Engineer. The goal should be to keep the batting average as high as it can be over time with the understanding that sometimes there will be strikeouts.
Hiring Guideline #1 – Hire for ability. Personally, I choose to eschew coding tests. I really don’t care if someone knows how to write a bubblegum sort on a piece of paper. I don’t know that off the top of my head so why should I expect any Engineer on my team to know that? What is important is that the Engineer have the ability to go find and create that solution should it be needed. This is not an ability to go to Stackoverflow and copy a solution – it is an ability to go find a solution to a similar problem and have the ability to convert that to a solutino to the problem in front of them without external guidance. This is the capacity for someone to stand on their own two feet and determine task breakdown without needing a lot of hand-holding. This competency is huge in regards to the abilities that I need in order to be an effective Engineering Manager. You will need to determine the abilities that best fit your expectations and the needs of your team and look for these traits in an Engineer candidate. Hire for these abilities.
Hiring Guideline #2 – Use Testing Sparingly. YMMV. Going back to the experimental paper, the conclusion states that “The representativeness of these problems for programming tasks is unknown.” If specific tests are to be used then they should include targeted relevance to the problems and projects that the Engineer would be working on if hired. At least that way you might get some relevant data in seeing how a candidate would respond to a real issue that the team might face.
Hiring Guideline #3 – Look for the Skillsets of the 100X Engineer. In the post that kicked off this topic, “The 100X Engineer” the author calls out Communication, Creativity, Empathy, Negotiation, and Technical as skillsets that set people above regular Engineers. Seeking out these skills during interviews will help to identify the right people for the role. As the suggestion for doing hard skill testing is minimized here, these focus on the soft skills. Many Engineers will not do well with all of these but can still hit the achievements of being a 100X Engineer.
Hiring Guideline #4 – Make Sure the Understanding of the Role is Solid. This is important as the role that needs to be filled is not a job description. Yes, you will need a job description to post a job. But additional time and effort needs to be put into defining and understanding the role. Using the theoretical Engineer Chris from the example above, if Chris decided to leave and you could only hire 1 person to replace them then the role that needs to be filled is much larger than the Development Engineer job description that will likely be posted. Knowing what the role is going into the hiring process is critical to achieving hiring success.
Hiring Guideline #5 – Hire for Impact. At the end of the day the biggest factor is the impact that someone will have on the organization as a whole. Their ability to get work done. Their understanding to follow current business practices. Their capacity to fit into the culture. Their qualification at the many varied skillsets needed to be successful. The overall impact is a culmination of all of these things. Hire someone that can make the biggest impact on your team and organization and you will most likely find that you have a 100X-1000X’er on your hands.

In conclusion, whilst it is my humble opinion that the classical idea of a 10X Engineer is a flawed concept, there is plenty of value that can be gained through an analysis of the genesis and ideas around this topic. In no way will any team be able to get rid of ten 1X Engineers and replace them with a single 10X Engineer, even if the output of that Engineer routinely is 10 times faster, better, or both than each of the individual 1X Engineers. The Impact Theory of a 1000X Engineer further expands on the ideas presented in regards to a 100X Engineer and hopefully provides some additional insight that can help you create a highly functioning and eminently efficient Engineering team. It is my hope that these words can help with this effort and hopefully also spur thoughts and discussions regarding a 10X Engineer and I sincerely hope that someone can extend these conclusions further and I really look forward to one day reading about the 10,000X Engineer! Good luck, and thanks for reading!
Comments are closed, but trackbacks and pingbacks are open.